Pythonで定型文コピーの補助ツールを作った
最近、近々リメイク版と新作が出るとか出ないとかの某恐竜クラフトサバイバルなゲームを楽しんでいる。
しかしこのゲーム、バグなのか仕様なのか定期的にセーブデータが爆破されてしまうことに悩まされていた。
はじめのうちは序盤の緊張感を再びとか楽しんでいたのだが、あまりに頻発するのでチートコマンドのようなものに手を出すことを決意する。
このゲームでは幸い、欲しいアイテムやキャラを入手できたり、空中浮遊やすり抜けを行えるようにするなど、多くのことができるシステムが搭載されている。
ソロローカルなので一度使うと歯止めが利かなくなる恐れはあったが、セーブ爆破で心折られるよりはマシと割り切ることにした。(そもそも便利系MODを入れてたりでぬるい設定ではあったが)
タイトル見てこのページを開いてくれた人はなんのこっちゃねんとお思いかもしれない。
帰る前にもう数行読んでほしい。
このゲームの入手系コマンドはやたら長いのである!
当然間違えると何も起こらない。
つまり、コードを登録して何度も使いまわせるアプリケーションが欲しくなった...ので作ったという経緯説明をしたかったのだ。
というわけで本題...なのだが実は既に公開している。
珍しくReadmeまで用意している...のでここで書くことはほぼない。
のだが、せっかくなので紹介したい。
Table.jsonというファイルを編集することでコピーする文字列を登録することができる。
例えば、以下のようなファイル構造にすると
{ "乙 八千男": "乙 八千男", "読み": "Otsu Hachio", "性別": "男", "年齢": "28" }
このようなGUIが表示できるようになる。
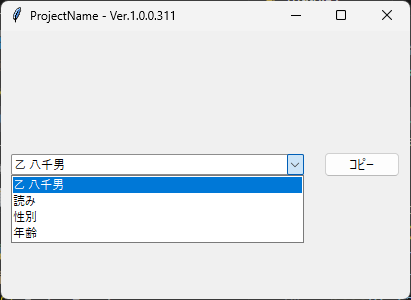
選択ボックスに反映されたキーを選んでコピーボタンをクリックすると、対応する値がクリップボードにセットされるというシンプルな仕組みである。
つまり読みを選択した状態でコピーするとOtsu Hachioがセットされる。
さらに以下のようなファイル構造にすることもできる。
{ "乙 八千男": { "名前": "乙 八千男", "読み": "Otsu Hachio", "性別": "男", "年齢": "28" }, "乙女 八千代": { "名前": "乙女 八千代", "読み": "Otome Yachiyo", "性別": "女", "年齢": "25", "趣味": "音楽" } }
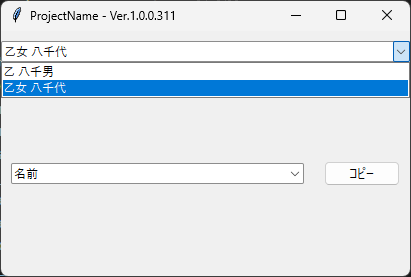
上の選択ボックスで人物を選び、下の選択ボックスでキーに対応する情報をコピーできる。
最後に以下のような構造にすることもできる。
{ "乙 八千男": { "ソシャゲ1": { "id": "sg_id1", "password": "sg_password1" }, "ソシャゲ2": { "id": "sg_id2", "password": "sg_password2" } }, "乙女 八千代": { "フリマ": { "id": "frema_id", "password": "frema_password" } } }
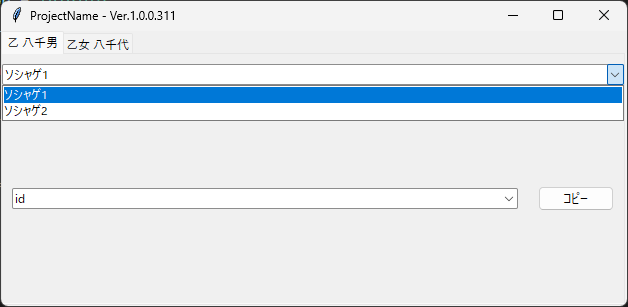
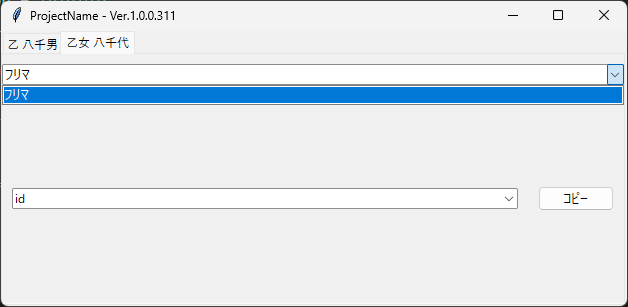
人物タブを選び、分類を選び、キーに対応する値をコピーすることができる。
ちなみに作成者自身は最後の構造を利用して
バニラ|MOD_A|MOD_B|...のようなタブを作り、さらに
建材入手系|キャラ入手系|その他のような分類を作ってコマンドを登録している。
もし興味を持ったらGithub - OtsuTableClipperで表示されている手順を見て使ってみてほしい。
Readmeのここがわからんとかあったら教えてもらえると大変うれしい。ナルベクカイゼンスル...とオモウヨウナキガスル。
長らくwith文を勘違いしていたらしい
久々の更新。
あなたのwith文はどこから? 私はopen()から。
この時点で察したかもだが、with文で生成したインスタンスは使い捨てだと思っていたというだけの話。
では、なぜ勘違いをしていたのかという言い訳から。
さっそく以下のコードを見てほしい。
# shop.txtは後々書くコードでの出力結果。 io = open("shop.txt", "r", encoding="utf-8") for i in range(2): with io: for s in io: print(s.strip())
ioというTextIOWrapperインスタンスを生成して2回with文で内容を出力しようとしているだけのコードである。
おわかりいただけただろうか?
出力をご覧いただこう。
--- X月1日 ---
開店: OtsuShop
入店: C(22)
入店: C(29)
入店: C(19)
入店: A(23)
退店: A(23)
退店: C(29)
退店: C(22)
退店: C(19)
閉店: OtsuShop
B(27)は営業時間外のため入店できませんでした。
--- X月2日 ---
開店: OtsuShop
入店: A(27)
入店: A(29)
入店: C(20)
入店: C(22)
退店: C(20)
退店: A(27)
退店: C(22)
退店: A(29)
閉店: OtsuShop
C(29)は営業時間外のため入店できませんでした。
Traceback (most recent call last):
File ..., line 107, in <module>
with io:
ValueError: I/O operation on closed file.
2回目のwith文を使おうとするとエラーになるのである。
これはTextIOWrapperが不親切なのか趣味で書いてる程度の雑魚にはわからない仕方ない事情があってのことなのか定かではないが、withブロック終了時に呼び出される__exit__メソッドでファイルを閉じる処理?はしてくれるものの__enter__メソッドでファイルを開く処理?はしてくれないというだけのことらしい。
__enter__, __exit__は自作クラスでも実装することはあるものの、TextIOWrapperよろしく__enter__ではselfを返すだけでなにも行わず、__exit__で終了処理を実装するだけのものばかりであったので、今まで気づくことがなかった。
ではなぜ気付いたのかというと、threadingの排他制御Lockについて調べていた時にwith lock:のようなインスタンスでwithブロックに入るようなコードを見かけたからである。
冷静に考えると、インスタンス生成 -> __enter__呼び出しという流れなので当たり前なのだが、盲点であった。
しかし、Lockが特殊なのでは?と疑心暗鬼になっていたので以下のコードで試してみることにした。
import random as rnd from typing import Iterator, Self class Human: ID = {} __name: str __age: int def __new__(cls, name: str, age: int) -> Self: data = (name, age) if data in cls.ID: return cls.ID[data] self = super().__new__(cls) self.__name = name self.__age = age cls.ID[data] = self return self def __str__(self) -> str: return f"{self.__name}({self.__age})" class Shop(list[Human]): def __init__(self, name: str) -> None: self.__name = name self.__is_open = False super().__init__() def __enter__(self) -> Self: self.open() return self def __exit__(self, *ex) -> None: self.close() def __str__(self) -> str: return f"{self.__name}" def append(self, human: Human) -> None: if human in self: return if not self.__is_open: print(f"{human}は営業時間外のため入店できませんでした。") return print(f"入店: {human}") super().append(human) def remove(self, human: Human) -> None: if human not in self: return print(f"退店: {human}") super().remove(human) def close(self) -> None: while self: human = rnd.choice(self) self.remove(human) self.__is_open = False print(f"閉店: {self}") def open(self) -> None: self.__is_open = True print(f"開店: {self}") def create_human() -> Iterator[Human]: names = tuple( chr(x) for x in range( ord("A"), ord("D"), ) ) ages = tuple(range(18, 30)) while True: yield Human(rnd.choice(names), rnd.choice(ages)) def main() -> None: shop = Shop("OtsuShop") gen_customer = iter(create_human()) for day in range(2): print(f"--- X月{day+1}日 ---") with shop: while len(shop) < 4: shop.append(next(gen_customer)) shop.append(next(gen_customer)) print() if __name__ == "__main__": main()
Shopクラスは開店, 閉店という状態を持ち、閉店中はappendできないリストの拡張クラス。
__enter__呼び出しで開店し、__exit__呼び出しで今いる客が全員退店し、閉店する。
あとは先ほどと同じようにwith shop:が2回発生するようにfor文を回している。
withブロック中にshopに客を4人入れ、さらにwithブロック外でshopに客を1人入れている。
--- X月1日 --- 開店: OtsuShop 入店: C(22) 入店: C(29) 入店: C(19) 入店: A(23) 退店: A(23) 退店: C(29) 退店: C(22) 退店: C(19) 閉店: OtsuShop B(27)は営業時間外のため入店できませんでした。 --- X月2日 --- 開店: OtsuShop 入店: A(27) 入店: A(29) 入店: C(20) 入店: C(22) 退店: C(20) 退店: A(27) 退店: C(22) 退店: A(29) 閉店: OtsuShop C(29)は営業時間外のため入店できませんでした。
withブロック入りで開店: OtsuShopが出力され、4人入店した時点でwithブロックを抜けると退店ログが続いた後閉店: OtsuShopと出力される。
その後入店しようとした客に対しては入店ができていないことが分かる。
しかし、もう一度withブロックに入ると再び客を受け入れることができるようになっている。
このように複数回with文を使えるかはクラスの実装次第であるということが納得できた。
Bluetooth完全ワイヤレスイヤホンがしばらく使用できなくなったときの覚書
いい加減放置しすぎなので雑記更新。
専門家ではないので正しい対処かどうかはわからないが、とりあえず解決したのでメモ。
発生状況
その日の条件
- 冬の外出
- ナイロンが主成分のコートのフードを被っていた
症状
- 突然音楽が消える
- イヤホンのすべての操作が不可能になる
- 「ザー」というノイズ音みたいなものが小さく聞こえる
- 充電ケースに戻すと、充電ケースの充電中を示すライトが点灯する
- しばらく待ってから再度取り出して使用を試みても
2と3の症状のまま
その日の条件時点で勘付いたかもしれないが、おそらく静電気由来の不具合が原因だったと思われる。1
帯電?
対処
- 充電ケースに入れずにしばらくイヤホン本体を放置してみる
- 「ザー」というノイズ音が聞こえなくなったら十分に充電する
- 再度ペアリング、または機器への接続
以上の手順で今回のトラブルは解決することができた。
同様の症状すべてに効果があるわけではないだろうが、もし、似た症状で困っていたら試す価値くらいはある……かも。
-
ちなみに自分は有線イヤホンが何にも接続していない場合にはノイズ音がなく、無音のパソコンに接続した場合に同様のノイズ音が聞こえたため気付いた。↩
Pythonでフォルダの変更を監視・連番リネームするライブラリ
何日か前に作って公開するか悩んでた奴の紹介。
c:直下でやったらえらい目にあったなどの苦情は懸念されるが、このブログ頭にデカデカ表記している文言とそもそもブログ見に来てるやつそんなにいないから大丈夫を頼りに公開に踏み込む。
機能はタイトル通りフォルダ内の変更を監視・連番リネームができる。
この連番リネームが上記c:直下など、ソフトを動かすのに必要なファイルまでリネームしてしまう可能性があるので、絶対に自分で変更対象のファイルがどんなものなのか把握しているフォルダでのみ使用するように。
一応、管理者権限のある状態で実行できないようにしているのでc:直下なんかだとPermissionErrorしてくれると思うが試す勇気はない!
例えば画像ファイルや、メモ書きなんかしか入っていないフォルダで使うことを想定してのライブラリ。
完成品は既にgitに上がっているので、駆け足で紹介。
実装についてもそこで確認してもらえれば。
コードは完全にWindows用のもの。
明確にWindowsでしか使えないのは以下の権限確認部分のみなので、そこを消すか別OSの権限確認処理に差し替えれば動く……かも。
バージョン2022.8.12にアップデートしました。
この更新でリネーム処理が高速化する……はず。
pip install -U git+https://github.com/Otsuhachi/OtsuFolderSerialRenamer.git#egg=otsufolserren
OtsuFolderSerialRenamer
│ LICENSE
│ Pipfile
│ Pipfile.lock
│ README.md
│ setup.py
│
└─otsufolserren
│ cfg.py
│ funcs.py
│ orders.py
│ __init__.py
│
├─monitoring
│ classes.py
│ __init__.py
│
└─serial_renamer
classes.py
__init__.py
otsufolserren直下にある__init__.pyにある以下のコードが権限確認部分。
import ctypes if ctypes.windll.shell32.IsUserAnAdmin() == 1: msg = f'このライブラリは重要なファイル構成を破壊する恐れがあるため、管理者権限で実行することはできません。' raise PermissionError(msg) del ctypes
余力があればGUIで使いやすくしたりして、このブログで紹介していきたい。
以下動作確認用のコードの説明。
テキストの中身とファイル名がバラバラ1のテストフォルダを実行ディレクトリと同じフォルダに作成し、そのフォルダのファイルを削除、追加、改名など弄ってからr, ro, cなど試したい操作を標準入力することで確認ができる。
今回のテストでは.txtファイル以外を想定していないので、注意2。
eで終了。
import random import shutil import time from pathlib import Path from typing import Iterable from otsufolserren import ORDER_CTIME, FolderSerialRenamer, get_fm from otsutil import setup_path from otsuvalidator import VInt ROOT = Path('otsufolserren_test_dir') CACHE = Path('otsufolserren_test_cache') def create_test(sample_number: int = 10) -> None: """テストフォルダを初期化します。 Args: sample_number (int, optional): テストフォルダ内に生成するファイル数です。 """ if ROOT.exists(): for p in ROOT.iterdir(): if p.is_file(): p.unlink() else: shutil.rmtree(p) sample_number = VInt(0).validate(sample_number) digit = len(str(sample_number)) for i, n in enumerate(random.sample(range(1, sample_number + 1), sample_number)): i += 1 if i > 1: time.sleep(0.3) n = f'{n:0{digit}d}' i = f'{i:0{digit}d}' with open(setup_path(ROOT / f'{n}.txt'), 'w', encoding='utf-8') as f: f.write(f'This file is No.{i}.') def remove_test() -> None: """テストフォルダを除去します。 """ if ROOT.exists(): shutil.rmtree(ROOT) if CACHE.exists(): shutil.rmtree(CACHE) def rfiles() -> Iterable[Path]: """テストフォルダ直下のファイルを返します。 Raises: FileNotFoundError: テストフォルダが存在しない場合に投げられます。 Returns: filter[Path]: テストフォルダ直下のファイルです。 """ if not ROOT.exists(): raise FileNotFoundError(ROOT) return filter(Path.is_file, ROOT.iterdir()) def show_files() -> None: """テストフォルダ内のフォルダを読み込み以下の形式で出力します。 <ファイル名>: <ファイルの内容> """ try: for file in rfiles(): try: with open(file, 'r', encoding='utf-8') as f: line = f.read() except: continue print(f'{file.name}: {line}') except: pass def ask_prompt(question: str, *answer: str) -> str: """質問に対して特定の回答以外なら再回答を促し、回答結果を返します。 Args: question (str): 質問です。 Raises: ValueError: answerが指定されていない場合に投げられます。 Returns: str: answerのいずれかです。 """ if not answer: msg = '1つ以上answerを指定してください。' raise ValueError(msg) answer_ = set(map(lambda x: x.lower(), answer)) while True: ans = input(question).lower() if ans in answer_: return ans def main(): create_test() fm = get_fm(ROOT, 'f', cache_dir=CACHE) help_str = 'c: 更新を確認します。\nr: リネームを実行します。\nro: only_when_changeをFalseにしてリネームを実行します。\nntmp: name_templateを変更します。\nfiles: ファイルとその中のテキストを表示します。\nh: このヘルプを再表示します。\ne: このスクリプトを終了します。' with FolderSerialRenamer(fm, 'td-', ORDER_CTIME) as fsr: print(help_str) while True: cmd = ask_prompt('実行する操作を指定してください。> ', 'c', 'r', 'ro', 'ntmp', 'files', 'h', 'e') if cmd == 'c': if fsr: l, diff = fsr.get_difference() print(f'{l}件の変更を検出しました。') if ask_prompt('表示しますか?(y/n)> ', 'y', 'n') == 'y': for d in diff: print(d) elif cmd in ('r', 'ro'): preview = fsr.get_preview() fsr.rename(only_when_change=cmd == 'r', preview=preview) preview = {x: y for x, y in preview.items() if str(x.resolve()) != str(y.resolve())} for b, a in preview.items(): print(b, '-->', a) elif cmd == 'ntmp': ntmp = input('新しいname_templateを入力してください。> ') fsr.name_template = ntmp elif cmd == 'files': show_files() elif cmd == 'h': print(help_str) elif cmd == 'e': break remove_test() if __name__ == "__main__": main()
Pythonで文字列をモールス信号に変換する -実装編-
2021-10-13 追記
前回に引き続き文字列をモールス信号に変換するライブラリを作ってみる(実装編)。
細かく分けていって最後に全部まとめたコードを紹介するので、内容だけ見たい場合はここをクリック
コードはWindows用のものなので別OSで使いたい場合は一部コードを差し替える。
具体的には、以下の2点を変更すればよい。
winsoundをインポートする文を消去する。winsoud.Beepの代わりに周波数とミリ秒を指定して音を鳴らすBeep関数を用意する。
目次
インポート
必要なライブラリをインポートしていく。
使用するのは、time.sleep, winsound.Beep, otsuvalidator, それからコーディングの補助でtyping.castをインポートしている。
otsuvalidatorはクラスの属性が適正かどうかを確認するライブラリなので、pip[env] install otsuvalidator等でインストールするか、嫌なら適宜属性チェックを行うメソッドを実装して差し替えるとよい。
typing.castはバリデータを元の型として扱う、コーディングの補助目的なので、不要であればその部分を差し替えればよい。
Windows以外のOSを使用する場合は、周波数とミリ秒を指定して音を鳴らすBeep関数を用意しておくこと。
以下がインポート部分のコード
import time from typing import cast from winsound import Beep from otsuvalidator import VInt, VRegex, VString
変換テーブルの作成
このライブラリのある意味本体ともいえる変換テーブルの作成をしていく。
<元の文字>:<0と1のみのタプル>という形式の辞書。
それから、復元用のテーブルも作成する。
こちらは<0と1のみのタプル>:<元の文字>という形式の辞書。
短点を0, 長点を1として扱う。
今回は一部記号とアルファベット、数字のテーブルを作ったが、アルファベットではなく平仮名やカタカナを使ったり、両方用意して後述のコードにmode属性なりを追加して参照するテーブルを使い分ければ、和英を切り替えることができるようになる。1
以下が変換テーブル部分のコード
# この上にインポート部分 C2M_TABLE = { '.': (0, 1, 0, 1, 0, 1), ',': (1, 1, 0, 0, 1, 1), '?': (0, 0, 1, 1, 0, 0), '_': (0, 0, 1, 1, 0, 1), '+': (0, 1, 0, 1, 0), '-': (1, 0, 0, 0, 0, 1), '×': (1, 0, 0, 1), '^': (0, 0, 0, 0, 0, 0), '/': (1, 0, 0, 1, 0), '@': (0, 1, 1, 0, 1, 0), '(': (1, 0, 1, 1, 0), ')': (1, 0, 1, 1, 0, 1), '"': (0, 1, 0, 0, 1, 0), '\'': (0, 1, 1, 1, 1, 0), '=': (1, 0, 0, 0, 1), 'A': (0, 1), 'B': (1, 0, 0, 0), 'C': (1, 0, 1, 0), 'D': (1, 0, 0), 'E': (0, ), 'F': (0, 0, 1, 0), 'G': (1, 1, 0), 'H': (0, 0, 0, 0), 'I': (0, 0), 'J': (0, 1, 1, 1), 'K': (1, 0, 1), 'L': (0, 1, 0, 0), 'M': (1, 1), 'N': (1, 0), 'O': (1, 1, 1), 'P': (0, 1, 1, 0), 'Q': (1, 1, 0, 1), 'R': (0, 1, 0), 'S': (0, 0, 0), 'T': (1, ), 'U': (0, 0, 1), 'V': (0, 0, 0, 1), 'W': (0, 1, 1), 'X': (1, 0, 0, 1), 'Y': (1, 0, 1, 1), 'Z': (1, 1, 0, 0), '1': (0, 1, 1, 1, 1), '2': (0, 0, 1, 1, 1), '3': (0, 0, 0, 1, 1), '4': (0, 0, 0, 0, 1), '5': (0, 0, 0, 0, 0), '6': (1, 0, 0, 0, 0), '7': (1, 1, 0, 0, 0), '8': (1, 1, 1, 0, 0), '9': (1, 1, 1, 1, 0), '0': (1, 1, 1, 1, 1), } M2C_TABLE = {x[1]: x[0] for x in C2M_TABLE.items()}
算術記号×とアルファベットXは(1, 0, 0, 1)と同じ値になってしまっている。
また、モールス信号から文字に変換する際のテーブルはC2M_TABLEのキーと値を反転させたものになっている。
この場合、キーが重複した場合に値が上書きされてしまう。
そのため、記号よりも後にアルファベットの登録を行って×ではなくXと対応するようにしている。
クラス定義
モールス信号クラスを作成していく。
それから、今回モールス信号に変換可能な文字列を表す正規表現MORSE_CODE_REGEXも定義しておく。2
基礎
まずはクラス属性と__init__(), __str__(), __add__()メソッド。
それからmorse_codeプロパティを定義していく。
以下が該当部分のコード。
# この上にインポート部分 # この上に変換テーブル部分 MORSE_CODE_REGEX = '^[A-Z0-9 \\.,\\?_\\+\\-×\\^\\/@\\(\\)"\'=]*$' class MorseCode: """モールス信号クラスです。 文字列のモールス表現を取得したり、モールス信号音を再生することができます。 """ text: str = cast(str, VRegex('^[A-Z0-9 \\.,\\?_\\+\\-×\\^\\/@\\(\\)"\'=]*$', 1)) short: str = cast(str, VString(1, 1)) long: str = cast(str, VString(1, 1)) sep: str = cast(str, VString(1, 1)) frequency: int = cast(int, VInt(37, 32767)) minimum_length: int = cast(int, VInt(1)) def __init__(self, text: str, *, short: str = '.', long: str = '-', sep: str = ' ', frequency: int = 440, minimum_length: int = 100): """textを表現するモールス信号を生成します。 textに含むことができる文字は"A-Z0-9 .,?-@"です。 また、連続する空白は1つとして扱われます。 Args: text (str): 元となる文字列です。 short (str, optional): 短点に使用する文字です。 long (str, optional): 長点に使用する文字です。 sep (str, optional): 文字間の区切りに使用する文字です。 frequency (int, optional): 再生時の周波数Hzです。 minimum_length (int, optional): 再生時の短点の長さです。 Raises: ValueError: short, long, sepに重複する文字をあてることはできません。 """ if len({short, long, sep}) != 3: msg = 'short, long, sepはそれぞれ違う文字である必要があります。' raise ValueError(msg) self.short = short self.long = long self.sep = sep self.frequency = frequency self.minimum_length = minimum_length while ' ' in text: text = text.replace(' ', ' ') self.text = text.upper() ct = C2M_TABLE s = self.short l = self.long res = [] for c in self.text: if c == ' ': res.append(' ') else: res.append(''.join(map(lambda x: l if x else s, ct[c]))) self.__morse_code = self.sep.join(res) def __str__(self) -> str: return self.text def __add__(self, other) -> 'MorseCode': kwargs = { 'short': self.short, 'long': self.long, 'sep': self.sep, 'minimum_length': self.minimum_length, } if type(other) is MorseCode or type(getattr(other, 'text', None)) is str: kwargs['text'] = self.text + other.text else: kwargs['text'] = self.text + other return MorseCode(**kwargs) @property def morse_code(self) -> str: """モールス表現化した文字列を返します。 Returns: str: モールス表現です。 """ return self.__morse_code
属性はバリデータを本来の型として扱うためにcastしているので、不要であれば以下のtext属性の例を参考にして書き換える。
型ヒントがいらない場合
text = VRegex(MORSE_CODE_REGEX, 1)
castをインポートしたくない場合3
text: str = VRegex(MORSE_CODE_REGEX, 1) # type: ignore
otsuvalidatorをインストールしたくない場合にはpropertyでカプセル化して属性を保護したり、インスタンス生成時の引数が正しいかどうか判定する処理を追加しておく。
また、以降に紹介するコードも自身の選択に応じて微修正する。
__init__()の処理
短点,長点,文字間を表す文字が重複していないか確認を行うshort,long,sep,frequency,minimum_lengthを属性に代入する4textから連続する空白を取り除き、text.upper()を属性に代入する__morse_code属性にtextのモールス表現を代入する
__str__()はself.textを返すようにして、元の文を取得できるようにする。
morse_codeプロパティはself.textのモールス信号表現を返す。
__add__()の処理
otherに影響しない引数を辞書kwargsに登録しておくotherがMorseCodeインスタンスかstr型のtext属性を持つかどうかkwargs['text']にselfとotherのtext属性を足したものを代入するkwargs['text']にselfのtext属性とotherを足したものを代入する5
kwargsをアンパックして、MorseCodeインスタンスを生成し、返す
play
続いてモールス信号を再生するplayメソッドを定義していく。
以下が該当部分のコード。
# この上にインポート部分 # この上に変換テーブル部分 # この上にクラスの基礎 def play(self, repeat: int = 1, BT: bool = False, AR: bool = False): """モールス信号音を再生します。 Args: repeat (int, optional): 本文の繰り返し再生数です。 BT (bool, optional): 送信開始の合図を再生するかどうかです。 AR (bool, optional): 送信終了の合図を再生するかどうかです。 """ n = self.minimum_length ct = C2M_TABLE sep_dot = n / 1000 sep_char = sep_dot * 3 sep_word = sep_dot * 7 fq = self.frequency text = ' '.join([self.text for _ in range(repeat)]) if BT: text = '= ' + text if AR: text += ' +' for i, char in enumerate(text): if char == ' ': time.sleep(sep_word) continue elif i: time.sleep(sep_char) for j, dot in enumerate(ct[char]): if j: time.sleep(sep_dot) if dot: Beep(fq, n * 3) else: Beep(fq, n)
モールス信号では短点の長さが時間の基準となる。6
短点を1としたときの長さの関係は以下の通り。
| 点 | 長さ |
|---|---|
| 長点 | 3 |
| 点の間 | 1 |
| 文字の間 | 3 |
| 単語の間 | 7 |
モールス信号を送信開始する前と後に特定の信号BT, ARを、送信するらしいので、引数BT, ARでそれの有無を指定している。7
また、本文の再生回数を指定することができる。
minimum_lengthはミリ秒(1/1000秒)なので、time.sleepする際には1/1000する必要がある。
そこで、それぞれsep_dot, sep_char, sep_wordとして代入しておく。
textを再生回数、前後信号の有無等で整形したのち、for文で処理を行っている。
音を鳴らす際のBeepに関しては何度も書いている通りWindows以外のOSは別途用意しておくこと。
for文内の処理
textの1文字charとそのインデックスiのfor文
charが空白かどうか
sep_word待機してcontinueiが0ではないか
sep_char待機するcharのモールス表現dotとそのインデックスjのfor文
jが0ではないか
sep_dot待機するdotが長点かどうか
n * 3ミリ秒鳴らすnミリ秒鳴らす
クラス定義-parse_morse
モールス表現を復号化するparse_morseメソッドを定義していく。
これはクラスメソッドなので、インスタンスを生成せずに使うことができる。
以下が該当部分のコード。
# この上にインポート部分 # この上に変換テーブル部分 # この上にクラスの基礎 # この上にplayメソッド @classmethod def parse_morse(cls, code: str, *, short: str = '.', long: str = '-', sep: str = ' ', frequency: int = 440, minimum_length: int = 100) -> 'MorseCode': if len({short, long, sep, ' '}) > 4: msg = '3種類以上の文字を使用することはできません。' raise ValueError(msg) if len({short, long, sep}) != 3: msg = 'short, long, sepはそれぞれ違う文字である必要があります。' raise ValueError(msg) char = code.split(sep) table = M2C_TABLE text = [] for c in char: if c == '': if text[-1] == ' ': continue text.append(' ') else: pattern = [] for p in c: if p == long: pattern.append(1) elif p == short: pattern.append(0) else: msg = f'"{code}"をモールス信号として解釈できませんでした。' raise ValueError(msg) text.append(table[tuple(pattern)]) text = ''.join(text) return MorseCode(text, short=short, long=long, sep=sep, frequency=frequency, minimum_length=minimum_length)
引数はtextがcodeになっている点以外は__init__()と同じである。
注意点としてはcodeで使用する文字とshort, long, sepが対応している必要がある。
short='s'としている場合にcode中の短点を'.'で表すことはできない。
後述するfor文以降の処理
cを復元した文字を入れるリストtextを用意しておく。code.split(sep)の1文字cのfor文
cはshort, longからなる文字列。
cが空白かどうか
continuetextに空白を追加してcontinue0または1のみからなるリストpatternを用意するcの1点pのfor文
pがlongなら
patternに1を追加pがshortなら
patternに0を追加textにM2C_TABLE[tuple(pattern)]を追加するfor文を抜けたら
textを''で連結する。textやその他引数を使用してMorseCodeインスタンスを生成し、返す
完成コード
完成したコードは以下の通りとなる。
import time from typing import cast from winsound import Beep from otsuvalidator import VInt, VRegex, VString C2M_TABLE = { '.': (0, 1, 0, 1, 0, 1), ',': (1, 1, 0, 0, 1, 1), '?': (0, 0, 1, 1, 0, 0), '_': (0, 0, 1, 1, 0, 1), '+': (0, 1, 0, 1, 0), '-': (1, 0, 0, 0, 0, 1), '×': (1, 0, 0, 1), '^': (0, 0, 0, 0, 0, 0), '/': (1, 0, 0, 1, 0), '@': (0, 1, 1, 0, 1, 0), '(': (1, 0, 1, 1, 0), ')': (1, 0, 1, 1, 0, 1), '"': (0, 1, 0, 0, 1, 0), '\'': (0, 1, 1, 1, 1, 0), '=': (1, 0, 0, 0, 1), 'A': (0, 1), 'B': (1, 0, 0, 0), 'C': (1, 0, 1, 0), 'D': (1, 0, 0), 'E': (0, ), 'F': (0, 0, 1, 0), 'G': (1, 1, 0), 'H': (0, 0, 0, 0), 'I': (0, 0), 'J': (0, 1, 1, 1), 'K': (1, 0, 1), 'L': (0, 1, 0, 0), 'M': (1, 1), 'N': (1, 0), 'O': (1, 1, 1), 'P': (0, 1, 1, 0), 'Q': (1, 1, 0, 1), 'R': (0, 1, 0), 'S': (0, 0, 0), 'T': (1, ), 'U': (0, 0, 1), 'V': (0, 0, 0, 1), 'W': (0, 1, 1), 'X': (1, 0, 0, 1), 'Y': (1, 0, 1, 1), 'Z': (1, 1, 0, 0), '1': (0, 1, 1, 1, 1), '2': (0, 0, 1, 1, 1), '3': (0, 0, 0, 1, 1), '4': (0, 0, 0, 0, 1), '5': (0, 0, 0, 0, 0), '6': (1, 0, 0, 0, 0), '7': (1, 1, 0, 0, 0), '8': (1, 1, 1, 0, 0), '9': (1, 1, 1, 1, 0), '0': (1, 1, 1, 1, 1), } M2C_TABLE = {x[1]: x[0] for x in C2M_TABLE.items()} MORSE_CODE_REGEX = '^[A-Z0-9 \\.,\\?_\\+\\-×\\^\\/@\\(\\)"\'=]*$' class MorseCode: """モールス信号クラスです。 文字列のモールス表現を取得したり、モールス信号音を再生することができます。 """ text: str = cast(str, VRegex(MORSE_CODE_REGEX, 1)) short: str = cast(str, VString(1, 1)) long: str = cast(str, VString(1, 1)) sep: str = cast(str, VString(1, 1)) frequency: int = cast(int, VInt(37, 32767)) minimum_length: int = cast(int, VInt(1)) def __init__(self, text: str, *, short: str = '.', long: str = '-', sep: str = ' ', frequency: int = 440, minimum_length: int = 100): """textを表現するモールス信号を生成します。 textに含むことができる文字は"A-Z0-9 .,?-@"です。 また、連続する空白は1つとして扱われます。 Args: text (str): 元となる文字列です。 short (str, optional): 短点に使用する文字です。 long (str, optional): 長点に使用する文字です。 sep (str, optional): 文字間の区切りに使用する文字です。 frequency (int, optional): 再生時の周波数Hzです。 minimum_length (int, optional): 再生時の短点の長さです。 Raises: ValueError: short, long, sepに重複する文字をあてることはできません。 """ if len({short, long, sep}) != 3: msg = 'short, long, sepはそれぞれ違う文字である必要があります。' raise ValueError(msg) self.short = short self.long = long self.sep = sep self.frequency = frequency self.minimum_length = minimum_length while ' ' in text: text = text.replace(' ', ' ') self.text = text.upper() ct = C2M_TABLE s = self.short l = self.long res = [] for c in self.text: if c == ' ': res.append(' ') else: res.append(''.join(map(lambda x: l if x else s, ct[c]))) self.__morse_code = self.sep.join(res) def __str__(self) -> str: return self.text def __add__(self, other) -> 'MorseCode': kwargs = { 'short': self.short, 'long': self.long, 'sep': self.sep, 'minimum_length': self.minimum_length, } if type(other) is MorseCode or type(getattr(other, 'text', None)) is str: kwargs['text'] = self.text + other.text else: kwargs['text'] = self.text + other return MorseCode(**kwargs) @property def morse_code(self) -> str: """モールス表現化した文字列を返します。 Returns: str: モールス表現です。 """ return self.__morse_code def play(self, repeat: int = 1, BT: bool = False, AR: bool = False): """モールス信号音を再生します。 Args: repeat (int, optional): 本文の繰り返し再生数です。 BT (bool, optional): 送信開始の合図を再生するかどうかです。 AR (bool, optional): 送信終了の合図を再生するかどうかです。 """ n = self.minimum_length ct = C2M_TABLE sep_dot = n / 1000 sep_word = sep_dot * 7 sep_char = sep_dot * 3 fq = self.frequency text = ' '.join([self.text for _ in range(repeat)]) if BT: text = '= ' + text if AR: text += ' +' for i, char in enumerate(text): if char == ' ': time.sleep(sep_word) continue elif i: time.sleep(sep_char) for j, dot in enumerate(ct[char]): if j: time.sleep(sep_dot) if dot: Beep(fq, n * 3) else: Beep(fq, n) @classmethod def parse_morse(cls, code: str, *, short: str = '.', long: str = '-', sep: str = ' ', frequency: int = 440, minimum_length: int = 100) -> 'MorseCode': if len({short, long, sep, ' '}) > 4: msg = '3種類以上の文字を使用することはできません。' raise ValueError(msg) if len({short, long, sep}) != 3: msg = 'short, long, sepはそれぞれ違う文字である必要があります。' raise ValueError(msg) char = code.split(sep) table = M2C_TABLE text = [] for c in char: if c == '': if text[-1] == ' ': continue text.append(' ') continue pattern = [] for p in c: if p == long: pattern.append(1) elif p == short: pattern.append(0) else: msg = f'"{code}"をモールス信号として解釈できませんでした。' raise ValueError(msg) text.append(table[tuple(pattern)]) text = ''.join(text) return MorseCode(text, short=short, long=long, sep=sep, frequency=frequency, minimum_length=minimum_length)
使い方
上のコードをコピーして、別モジュールからインポートするも良し、同じファイルに書いて使用するも良し。
後日github経由のインストールくらいはできるようにする……かも?
インストールできるようになった。
やりかたはここ。githubのリポジトリはここ。
from morse_code import MorseCode # 同じフォルダ内の`morse_code.py`にコピーした場合 def show_morse(mc: MorseCode): print(f'"{mc}" "{mc.morse_code}"') # モールスインスタンス生成 paris = MorseCode('paris') show_morse(paris) # モールス + モールス(文字指定) hello = MorseCode('hello') python = MorseCode('python', short='0', long='1') show_morse(hello + python) # モールス + モールス(文字指定) show_morse(python + hello) # モールス + 文字列 show_morse(hello + ' otsuhachi') # モールス復号化 m2c = MorseCode.parse_morse('.- .-. . -.-- --- ..- - .... . .-. . ..--..') show_morse(m2c) # 再生 m2c.play(BT=True, AR=True) # モールス + 整数 (例外発生) # show_morse(hello + 1) """ Traceback (most recent call last): File "~\sandbox.py", line 24, in <module> show_morse(hello + 1) File "~\morse_code.py", line 133, in __add__ kwargs['text'] = self.text + other TypeError: can only concatenate str (not "int") to str """
"PARIS" ".--. .- .-. .. ..." "HELLOPYTHON" ".... . .-.. .-.. --- .--. -.-- - .... --- -." "PYTHONHELLO" "0110 1011 1 0000 111 10 0000 0 0100 0100 111" "HELLO OTSUHACHI" ".... . .-.. .-.. --- --- - ... ..- .... .- -.-. .... .." "ARE YOU THERE?" ".- .-. . -.-- --- ..- - .... . .-. . ..--.."
無事、作成することができた。
コードを書くよりも記事にする方が疲れる。
インストール
以下のコマンドを実行することでインストールできる。
pip install git+https://github.com/Otsuhachi/OtsuMorseCode
使い方は上で示した通り。
Pythonで文字列をモールス信号に変換する -定義編-
今回はタイトル通り文字列をモールス信号に変換するライブラリを作ってみる(定義編)。
実装編についてはこちら。
Windows限定で、他OS用の差し替えについては実装編の最後の方で少し触れる程度になる予定。
また自作ライブラリotsuvalidatorを使用するので(宣伝!)インストールが必要。
それ以外の非標準ライブラリは不使用。
仕様を決める
変換可能な文字列
対応するのは半角英数字と.,?_+-×^/@()"'=それから半角空白。
また、半角英字はすべて大文字に変換して扱う。
連続する空白は1つとして扱う。
和音対応を考えると重複するパターンが出てしまうので無し。
出力
文字列として出力した際には元のテキスト1を表示することにする。
またmorse_codeという属性でモールス表現を取得できるようにする。
インスタンス生成
引数として使用するのは以下の通り。
| 名前 | 型 | 概要 |
|---|---|---|
| text | str | モールスとして扱いたい文字列 |
| short | str | モールス信号の短点1として扱いたい文字 |
| long | str | モールス信号の長点1として扱いたい文字 |
| sep | str | モールス信号の文字間1に使用したい文字 |
| frequency | int | 再生時に使用する周波数37~32767の間 |
| minimum_length | int | 再生時の1音の長さ(ミリ秒) |
以上の内、必須なのはtextのみ。
short, long, sepは1文字でそれぞれ異なる必要がある。
minimum_lengthは再生時の基準となる長さ。
機能
| 関数 | 概要 | 備考 |
|---|---|---|
| play | モールス信号を再生する | |
| parse_morse | モールス表現からMorseCodeインスタンスを生成する |
クラスメソッド |
| __add__ | MorseCodeインスタンスまたはstr型+xでエラーが発生しないオブジェクトxからMorseCodeインスタンスを生成する本文以外の __init__用引数はselfから引き継ぐ |
足し算用のマジックメソッド |
play
モールス信号を再生する。
引数は以下の通り。
| 名前 | 型 | 概要 |
|---|---|---|
| repeat | int | 本文の繰り返し回数 |
| BT | bool | 本文再生前に送信開始の合図BTを再生するかどうか |
| AR | bool | 本文再生後に送信終了の合図ARを再生するかどうか |
必須引数は無し。
parse_morse
モールス表現を基にモールス信号インスタンスを生成する。
引数は以下の通り。
| 名前 | 型 | 概要 |
|---|---|---|
| code | str | モールス表現の文字列short, long, sepと半角空白以外の文字を含んではならない |
| short | str | モールス信号の短点[^2]として扱いたい文字 |
| long | str | モールス信号の長点[^3]として扱いたい文字 |
| sep | str | モールス信号の文字間[^4]に使用したい文字 |
| frequency | int | 再生時に使用する周波数37~32767の間 |
| minimum_length | int | 再生時の1音の長さ(ミリ秒) |
必須引数はcodeのみ。
注意点として、Xと×が同じモールス表現になるため1×2=2となるようなモールス表現を与えた場合1X2=2として解釈されてしまう。
__add__
MorseCodeインスタンス + objectという式を実行するためのマジックメソッド。
MorseCodeインスタンス += objectは非対応なので注意。
objectはMorseCodeインスタンスかstr + objectがエラーにならないものであればOK。
selfからtext以外のインスタンス生成で受け取る引数を受け継いで、新しいtextを持つMorseCodeインスタンスを生成する。
Python組み込み関数8 -chr・ord編-
Pythonおさらい第8段
制約として公式ドキュメントのみ参照*1として、読む癖をつける訓練も兼ねる。
今回はchr関数とord関数の2種類について。
chrは整数に対応する文字を返し、ordはその逆に文字に対応する整数を返す。
整数と文字の対応はUnicodeで参照しているらしい。
内容的にはそれで全部な気がするので、蛇足がいらなければここで終了、解散!
構成
今回の関数は以下のようになっている。
chr(i)
ord(c)
iはint型, cはstr型1を表す。
使ってみる
あ~んを表示させてみることにする。
また、変換前の整数については16進数で表す。
実行するコードは以下の通り。
for i in range(ord('あ'), ord('ん') + 1): print(f'{i:X} -> {chr(i)}')
3042 -> あ 3043 -> ぃ 3044 -> い 3045 -> ぅ 3046 -> う 3047 -> ぇ 3048 -> え 3049 -> ぉ 304A -> お 304B -> か 304C -> が 304D -> き 304E -> ぎ 304F -> く 3050 -> ぐ 3051 -> け 3052 -> げ 3053 -> こ 3054 -> ご 3055 -> さ 3056 -> ざ 3057 -> し 3058 -> じ 3059 -> す 305A -> ず 305B -> せ 305C -> ぜ 305D -> そ 305E -> ぞ 305F -> た 3060 -> だ 3061 -> ち 3062 -> ぢ 3063 -> っ 3064 -> つ 3065 -> づ 3066 -> て 3067 -> で 3068 -> と 3069 -> ど 306A -> な 306B -> に 306C -> ぬ 306D -> ね 306E -> の 306F -> は 3070 -> ば 3071 -> ぱ 3072 -> ひ 3073 -> び 3074 -> ぴ 3075 -> ふ 3076 -> ぶ 3077 -> ぷ 3078 -> へ 3079 -> べ 307A -> ぺ 307B -> ほ 307C -> ぼ 307D -> ぽ 307E -> ま 307F -> み 3080 -> む 3081 -> め 3082 -> も 3083 -> ゃ 3084 -> や 3085 -> ゅ 3086 -> ゆ 3087 -> ょ 3088 -> よ 3089 -> ら 308A -> り 308B -> る 308C -> れ 308D -> ろ 308E -> ゎ 308F -> わ 3090 -> ゐ 3091 -> ゑ 3092 -> を 3093 -> ん
今回の出力はここの表と対応しているのがわかる。
ordで取得できる整数は、4桁の16進数に変換して'\uXXXX'とすることでユニコードエスケープとして使用できる。
さらにchrで0xXXXXを調べることで元の文字を調べることもできる。
'\uXXXX'のような文字列を見かけた際は試してもいいかもしれない。
締め
今回紹介した関数はいまいち使いどころや魅力がよくわかっていない。
一応、上の例のように数字では範囲がよくわからないあ~んをrangeで指定することができているが、シンプルな50音を取得できているわけではないので、実用性という点では首を捻らざるを得ない。
A~Zであれば指定できるが……。
サニタイズや暗号化で使用するのだろうか……。
いまいち締まらないが、これ以上のことを書くこともできないのでこれにて。
Pythonではchar型が存在しないため
-
ただし1文字である必要がある↩
*1:わかりやすく解説している他サイトを見ない